
はじめに
本記事では2つのデータを比較する時に便利な関数を紹介します。
2つのデータ間の共通部分の値 や 異なる部分の値、どちらかに存在している値 などを調べる方法を紹介します。
なお今回紹介する関数はすべてdplyrパッケージに含まれる関数になっていますのであらかじめインストールしてライブラリーを呼び出しておく必要があります。
(baseパッケージにも同じ名前でほぼ同じ機能を持つ関数がありますがベクトルにしか対応しておらずデータフレームに使うことができません。)
今回紹介する関数
今回紹介する関数は以下の3つです。
- intersect: 2つのデータの共通部分の値だけを取得する関数
- setdiff: 2つのデータの異なる部分の値だけを取得する関数
- union : 2つのデータセットのどちらかに存在する値を取得する関数
それぞれの関数が取得する値をベン図で表すと以下の図のようになります。

注意点としては、これらの関数で取得するデータは自動的に重複なく値を取り出すため、複数個同じ値が含まれているデータに対して、その重複分を除きたくない場合は使えないようになっています。
共通部分の値を取得する関数
まずは共通する値を取り出すintersectです。
この関数の動作イメージはこんな感じです。

そして基本的な使い方は以下の通りです。
intersect( 1つめのデータ, 2つめのデータ)
上の図の処理を実行するコードは次の通りです。
library(tidyr) data1 = c(1:10) data2 = c(6:15) intersect(data1, data2) > [1] 6 7 8 9 10
今回は数字型のベクトルデータを扱いましたが、文字列でも同様に処理できますし、データフレームでも行名を用いて共通する行を取得することが出来ます!
異なる部分の値を取得する関数
異なる部分の値を取得する時はsetdiffを使います。
この関数の動作イメージは次の図のようになります。

そして基本的な使い方はこんな感じになります。
setdiff(1つめのデータ, 2つめのデータ)
上の図の処理を実行するコードは次の通りです。
library(tidyr) data1 = c(1:10) data2 = c(6:15) setdiff(data1, data2) > [1] 1 2 3 4 5
setdiffは第一引数に指定したデータ(上の例だとdata1)の中で第二引数に指定したデータ(上の例だとdata2)に含まれないものを取得する関数なので、どちらを第一引数に指定するかで結果が変わります。
またこの関数も数字型ベクトル文字型ベクトル、データフレームなどに用いることができます。
どちらかに存在する値を取得する関数
少なくともどちらかのデータセットに含まれている値を取得する時はunion関数を用います。
この関数の動作イメージは次の図のようになります。
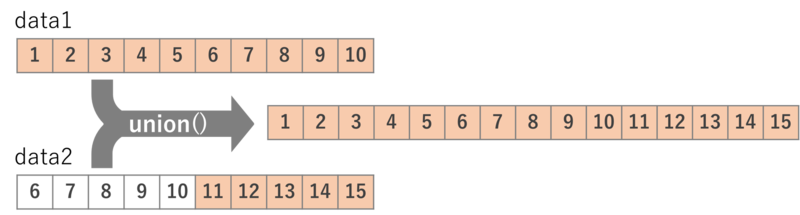
上の図の処理を実行するコードは次のとおりです。
library(tidyr) data1 = c(1:10) data2 = c(6:15) union(data1, data2) > [1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
この関数はどちらかに入っている値をとってくる関数ですが、複数回出てくる値も1つにまとめられてしまうので、どちらかに含まれているすべての値をとってきていると思って値の数をカウントすると、実は複数回出てくる値はうまくカウントできていないということもあるので、あくまでどちらかのデータに含まれている値を重複なく取り出す関数だと考えて扱うことが重要です。
またこの関数も数字型ベクトル文字型ベクトル、データフレームなどに用いることができます。
注意点
初めにも書きましたが、対象の値を重複なく取り出す点には注意が必要です。
重複なく取り出すということのイメージですが、例えば以下の図のようになります。
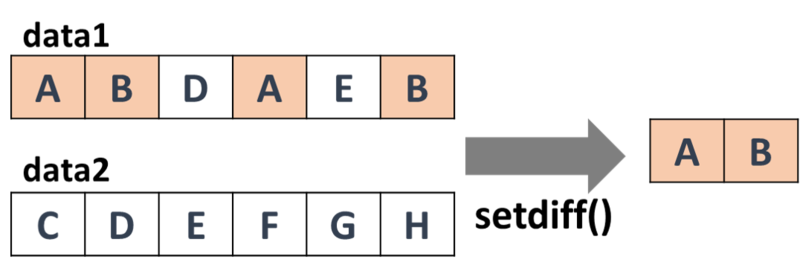
このような動作になることを忘れて処理していてもエラーは出ませんがデータの見落としなどが生じる危険性があります。
まとめ
今回は2つのデータを比較して共通の値やユニークな値などを取り出す関数を紹介しました。データの確認や集計などで使うことがあるかもしれないので便利な関数があった気がすると思い出せるように頭の片隅に入れておくと良いかもしれません。