はじめに
本記事ではRのtidyrパッケージの中の関数であるgather関数とspread関数を使いこなすために関数がどうようなイメージで動いているのかを紹介します。
gatherとspreadは使いこなせるとデータの操作が非常に効率的にできるようになるのでぜひ習得してみてください。
spread/gatherでできること
まずはどのようなことができるのかを紹介していきます。
spreadでできること
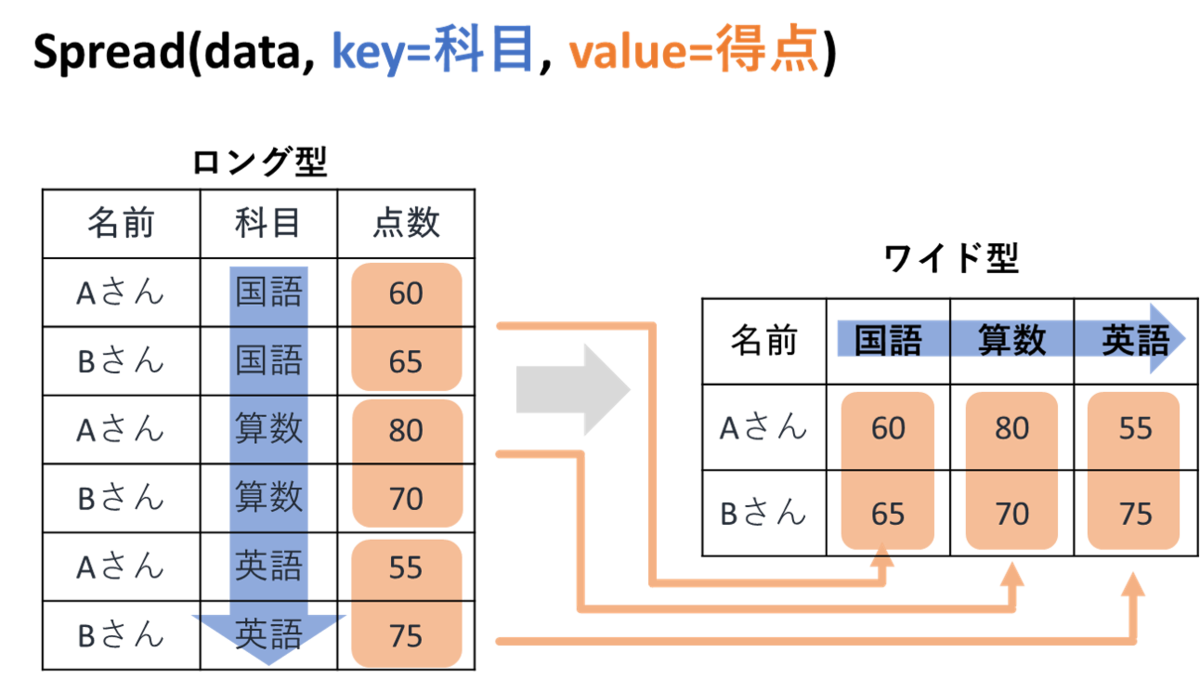
spreadはデータフレームをロング型からワイド型に変換することができます。
イメージとしては下の図のような感じになります。

gatherでできること
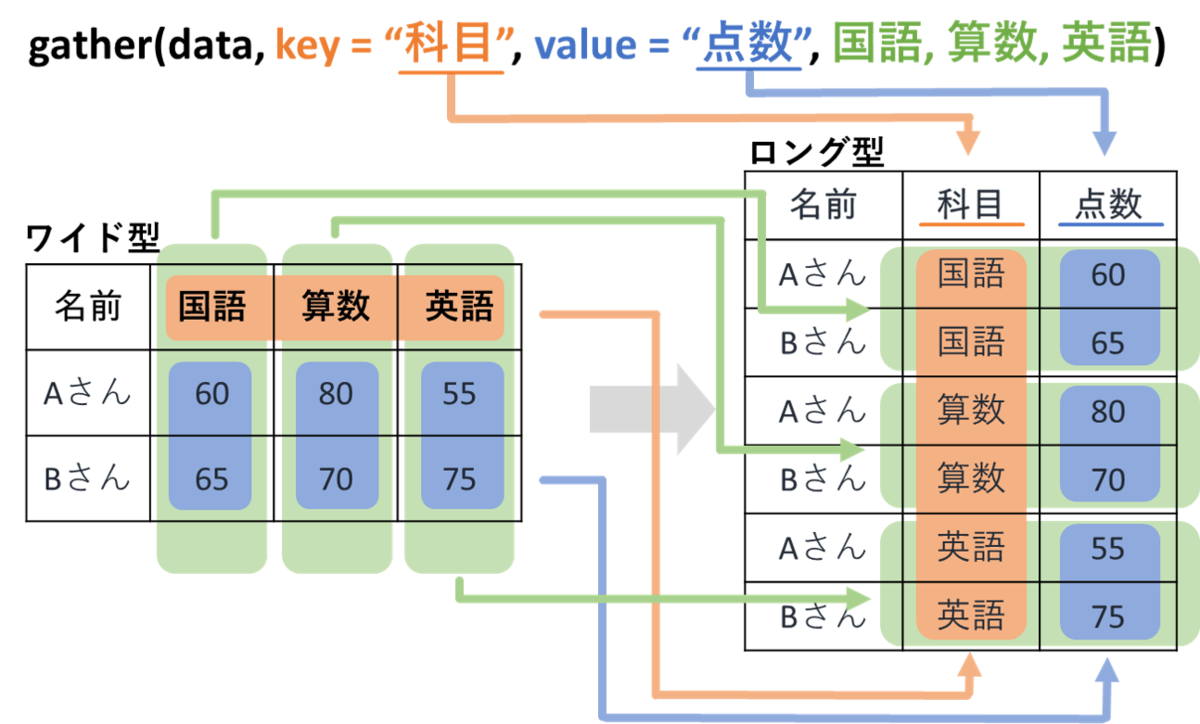
gatherはデータフレームをワイド型からロング型に変換することができます。
イメージとしては下の図のような感じになります。

gatherとspreadはどちらもデータフレームのワイド型とロング型の型を変換する時に便利な関数になっています。
上記2つの関数はお互いに対応している関数なのでセットで覚えて使えるようになるとデータ整理がはかどります。
spread/gatherの使い方
spread関数の使い方
spreadでは以下の項目を指定します。
- 対象とする型変形したいデータフレーム(data引数)
- 列名に持ってきたい列(key引数)
- 列の中身にしたい値が入った列(value引数)
spreadでできることで紹介したデータフレームの変形を実際におこなう場合は以下のコードで実行できます。
# パッケージの呼び出し library(tidyr) # 変換前のデータフレームの作成 data <- data.frame(名前 = rep(c("Aさん", "Bさん"), 3), 科目 = c(rep("国語",2), rep("算数",2), rep("英語", 2)), 得点 = c(60,65,80, 70, 55, 75)) # spreadを用いた変換 spread(data, key = 科目, value = 得点)
関数の動作イメージとしては下の図のようになります。
gather関数の使い方
gatherでは以下の項目を指定します。
- 型変形したいデータフレーム(data引数)
- もともと列名だった値が入る列の列名(key引数)
- 列の中身(値)だったものがまとめられる列の列名(value引数)
- ロング型にまとめる対象とする列の列名(対象の列を列挙して選択)
spreadでできることで紹介したデータフレームの変形を実際におこなう場合は以下のコードで実行できます。
# パッケージの呼び出し library(tidyr) # 変換前のデータフレームの作成 data <- data.frame(名前 = c("Aさん", "Bさん"), 国語 = c(60,65), 算数 = c(80,70), 英語 = c(55,75)) # gatherを用いた変換 gather(data, key = "科目", value = "点数", 国語, 算数, 英語)
関数の動作イメージとしては下の図のようになります。
まとめ
gatherとspreadはデータの変形にとても便利な関数です。統計解析を実施する前の段階でデータを整理する時に重宝すると思います。
この2つはお互いに対応する操作を行う関数ですが、引数の渡し方に違いがあるため、理解するのが大変だと思いますが、理解の助けになればと思います!